第33届ACM国际多媒体大会(The 33rd ACM International Conference on Multimedia,ACM MM 2025)将于2025年10月27日至10月31日在爱尔兰都柏林举行,是中国计算机学会CCF推荐的A类国际会议。厦门大学多媒体可信感知与高效计算教育部重点实验室共有20篇论文被录,录用论文简要介绍如下:(按第一作者姓氏笔画排序)
录用论文简要介绍如下:
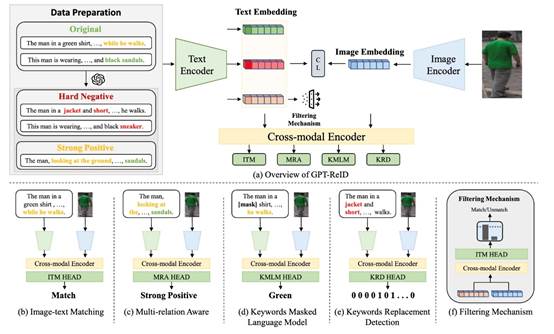
01. GPT-ReID: Learning Fine-grained Representation with GPT for Text-based Person Retrieval
介绍:本文提出了一种名为 GPT-ReID 的新颖框架,用于文本描述驱动的行人检索任务(Text-Based Person Retrieval, TBPR)。该方法充分利用大语言模型(LLMs)的强大生成与理解能力,通过引入 GPTGAN 模块生成高质量的增强数据,包括强正样本描述与难负样本描述,缓解了数据不足和过拟合问题。同时,设计了三个辅助任务:多关系感知(MRA)、关键词掩码语言建模(KMLM)与关键词替换检测(KRD),在全局与局部层面提升图文细粒度对齐能力。实验结果表明,GPT-ReID 在多个基准数据集上显著优于现有方法,验证了其在跨模态语义对齐与检索准确性方面的有效性。
本文第一作者是厦门大学人工智能研究院2022级硕士生王旭东,通讯作者是戴平阳高级工程师,由谭磊(新加坡国立大学)、曹刘娟教授共同合作完成。
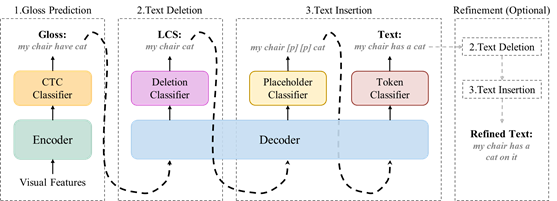
02. Gloss Matters: Unlocking the Potential of Non-Autoregressive Sign Language Translation
简介:虽然非自回归手语翻译(NASLT)模型在推理速度方面具有优势,但其译文质量却明显落后于最先进的自回归手语翻译(ASLT)模型。为了缩小这一质量差距,我们利用手势标注(gloss)来挖掘NASLT模型的潜力。具体而言,我们提出用于手语翻译任务的名为GLevT的模型,它将gloss作为编辑生成文本的初始序列。特别地,为了缓解GLevT的训练和推理之间由于引入gloss导致的不一致性,我们提出了一个双中心学习策略和一种基于关键帧的gloss替换方法改进GLevT的训练,进一步提高GLevT的译文质量。在CSL-Daily数据集上的实验表明,GLevT比其它NASLT模型在BLEU和ROUGE分数上高出约4个点,同时在推理速度上实现了3.46~5.26倍的加速;同时,GLevT与最先进的ASLT模型的翻译性能相当。此外,我们还将GLevT 扩展到无gloss的手语翻译任务上,仅使用49M的参数便取得与最先进的大型模型相当的翻译性能。
该论文的共同第一作者是厦门大学信息学院2020级博士生王志豪和厦门大学人工智能研究院2024级硕士生刘诗雨,通讯作者是苏劲松教授,由何志威(上海交通大学)、郑康杰(北京大学)和姚俊峰教授共同合作完成。
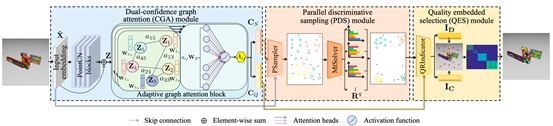
03. Adaptive Graph Attention-Guided Parallel Sampling and Embedded Selection for Multi-Model Fitting
简介:多模型拟合是计算机视觉中的一个基本挑战,现实世界的数据通常包含严重的噪声和伪异常值。现有方法依赖于低效的顺序假设和验证框架,需要预定义模型数量和内点阈值,然而这些参数在实际场景中很难确定。为了解决这些问题,本文提出了一种新的并行自适应图注意力引导的多模型拟合方法,该方法联合学习局部和全局特征,执行并行假设采样和质量嵌入模型选择。具体来说,本文设计了一个双置信图注意力模块,该模块采用自适应图注意力网络对数据关系进行建模,预测最小集置信度和质量置信度,以指导多模型拟合过程,从而消除手动参数调整。此外,本文提出了一种并行判别采样模块,该模块利用最小集置信度的同时对假设进行并行采样。通过设计量化一致性约束来最大化模型间方差和最小化模型内差异。为了获得高质量的模型,提出了一种质量嵌入式选择模块,该模块将质量置信度集成到模型选择和数据聚类的联合优化中,实现计算高效的模型选择和伪异常值抑制。
该论文第一作者是厦门大学信息学院2023级博士生尹文玉,通讯作者是王菡子教授,由David Suter教授(澳大利亚伊迪斯科文大学)、林舒源博士(暨南大学)共同合作完成。
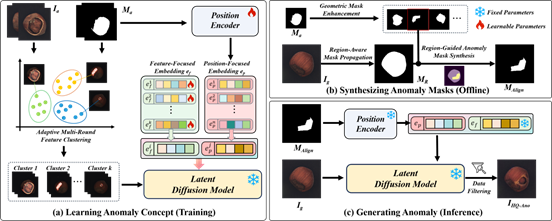
04. Generate Aligned Anomaly: Region-Guided Few-Shot Anomaly Image-Mask Pair Synthesis for Industrial Inspection
简介:工业异常检测受限于样本稀缺,而现有合成方法普遍存在真实感不足、掩模对齐不准及泛化性差等问题。为此,本文提出生成对齐异常(GAA),一种基于区域引导的小样本异常图像-掩模对生成框架。GAA创新性地利用预训练潜在扩散模型的强先验知识,通过三个关键模块实现高质量异常合成:首先,局部概念分解模块联合建模异常语义特征与空间分布,实现对异常类型及位置的细粒度控制;其次,自适应多轮聚类模块对异常概念进行层次化语义聚类,增强表征一致性;最后,区域引导掩模生成与质量过滤模块通过空间约束确保异常-掩模精确对齐,并引入低质量样本过滤机制提升合成数据可靠性。在MVTec AD与LOCO数据集的广泛实验表明,GAA在异常合成质量及下游定位、分类任务中均展现出显著优势。
该论文第一作者是厦门大学信息学院2023级硕士生卢轶霖,通讯作者是张声传副教授,由2023级博士生林将航、2022级硕士生谢林煌、赵凯(VIVO)、2023级博士曲延松、曹刘娟教授、纪荣嵘教授等共同合作完成。
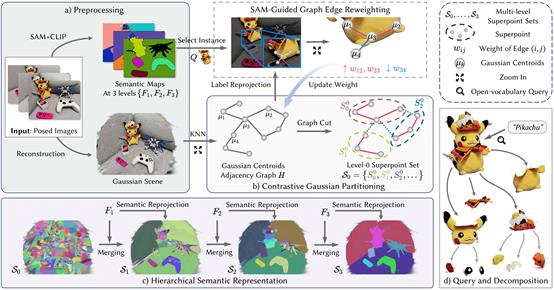
05. Training-Free Hierarchical Scene Understanding for Gaussian Splatting with Superpoint Graphs
简介:现有基于三维高斯泼溅的场景理解方法依赖逐视角的二维语义优化过程,训练过程缓慢且难以保持跨视角的语义一致性。本文提出一种无需训练的开放词汇三维场景理解框架:首先在三维高斯场景中进行基于对比式分割,提取空间紧凑、语义一致的超点;随后引入多粒度SAM掩码引导超点逐层合并,构建具备部件到物体层级结构的超点图;再通过高效的反投影策略,将二维语义特征直接映射到各级超点,构建出结构完备、多视角一致的三维语义场。该框架消除了迭代训练开销,同时支持粗粒度目标与细粒度部件的开放词汇查询、交互式分割。实验结果表明,本文的方法在多个开放词汇基准数据集上取得了最先进的分割性能,同时语义场构建速度提升超过30倍,这验证了其在高效三维场景理解中的实用价值。
该论文共同第一作者是厦门大学信息学院2024级硕士研究生代绍辉和2023级博士研究生曲延松,通讯作者是曹刘娟教授,由2022级本科生李哲彦、2023级博士生李新阳、张声传副教授共同合作完成。
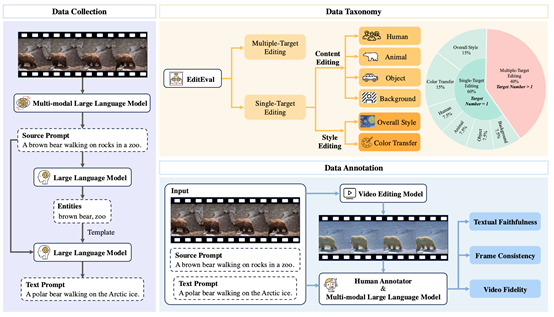
06. EditEval: Towards Comprehensive and Automatic Evaluation for Text-guided Video Editing
简介:现有视频编辑模型的自动评测指标往往与人工标注结果不一致,迫使研究者依赖耗时且难以客观统一的人工标注。为解决这一痛点,本文构建迄今规模最大的文本指导视频编辑评测基准EditEval,涵盖200段原始视频及1010条多样化文本提示,并从中抽取160个实例以8个主流开源模型生成1280段编辑结果并配以人工标注,从文本忠实度、帧间一致性、视频保真度三大维度全面衡量模型表现;同时提出自动评测方案EditScore,借助多模态大语言模型(MLLM)的推理与理解能力对上述维度统一打分。实验显示目前最佳视频编辑模型在EditEval上平均仅得 3.16/5 分,而在文本忠实度上EditScore(基于LLaVA-One-Vision-7B)与人工标注的Pearson相关性显著优于传统CLIP指标(0.50 vs 0.22),充分彰显任务挑战性与MLLM评测潜力。
该论文的共同第一作者是厦门大学信息学院2023级硕士生刘冰帅、2022级博士生王安特和2023级硕士生闵子君、通讯作者是苏劲松教授,由吕晨阳(阿里国际)、王龙跃(阿里国际)、2020级博士生王志豪、韩旭(清华大学)、李鹏(清华大学)共同合作完成。
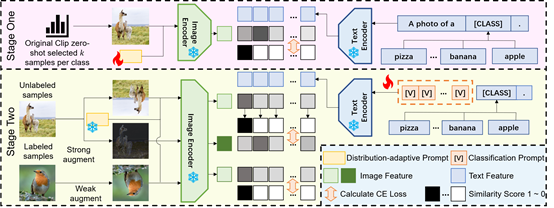
07. FATE: A Prompt-Tuning-Based Semi-Supervised Learning Framework for Extremely Limited Labeled Data
简介:半监督学习通过利用有标签数据和无标签数据取得了重大进展。但是现有的半监督学习方法忽略了一个常见的现实世界场景,即有标签数据极其稀缺,在数据集中每一类可能仅有1或者2个有标签数据。在这种约束下,一般的半监督学习方法很难训练出一个有效的骨干网络,而利用预训练模型的方法往往无法在利用有限的有标签数据和大量的无标签数据之间找到最佳平衡点。为了应对这一挑战,本文提出了先适应,后分类框架——FATE,这是一种为有标签数据极其有限的场景量身定制的新型半监督学习框架。其核心思路为:通过两阶段的快速预训练模型提示调优技术,利用大量的无标签数据来补偿稀缺的监督信号,然后转移到下游分类任务。FATE与视觉和视觉语言预训练模型均有良好的兼容性。广泛的实验表明,FATE有效地缓解了半监督学习中有标签数据极端稀缺带来的挑战,与最先进的半监督学习方法相比,在七个基准测试中平均性能提高了33.74%。
该论文的第一作者是厦门大学信息学院2023级硕士生刘赫昭,通讯作者是卢杨助理教授,由李梦柯(深圳大学)、张逸群(广东工业大学)、Shreyank N Gowda(英国诺丁汉大学)、宫辰(上海交通大学)、王菡子教授共同合作完成
08. HCCM: Hierarchical Cross-Granularity Contrastive and Matching Learning for Natural Language-Guided Drones
简介:自然语言引导无人机为目标匹配与导航等任务提供了灵活的交互方式,但其广阔视野和复杂语义关系对视觉语言理解提出了更高要求。现有视觉语言模型多聚焦全局对齐,缺乏细粒度理解,而层次建模方法又依赖精确实体划分与严格语义关系,难以适应复杂场景。为此,我们提出分层跨粒度对比与匹配学习(HCCM)框架,其包含两个核心模块:区域-全局图文对比学习(RG-ITC)通过局部与全局语义对比建模跨模态层次关系;区域-全局图文匹配学习(RG-ITM)则评估局部与全局间的语义一致性,无需严格关系约束。此外,为缓解无人机场景中文本描述不完整或歧义问题,HCCM引入动量对比与蒸馏机制(MCD)增强对齐鲁棒性。实验证明,HCCM在GeoText-1652上达到了最优性能,图像与文本检索的Recall@1分别为28.8%和14.7%,并在未见的ERA数据集上实现39.93%的平均召回,展现出优异的泛化能力和鲁棒性。
该论文第一作者是厦门大学信息学院2024级硕士研究生阮豪,通讯作者是罗志明副教授,由林金亮、赖映鑫、李绍滋教授共同合作完成。
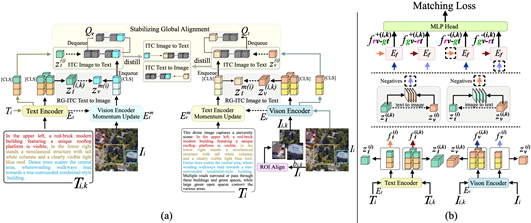
09. Novel Category Discovery with X-Agent Attention for Open-Vocabulary Semantic Segmentation
简介:开放词汇语义分割 (OVSS) 通过文本驱动的对齐进行像素级分类,其中基础类别训练与开放词汇推理之间的领域差异对潜在未见类别的判别建模提出了挑战。为了应对这一挑战,现有的基于视觉语言模型 (VLM) 的方法通过预训练的多模态表征展现出令人赞叹的性能。然而,潜在语义理解的基本机制仍未得到充分探索,这成为OVSS发展的瓶颈。本研究发起了一项探索性实验,旨在探索归纳学习范式下VLM中潜在语义的分布模式和动态。基于这些洞察,本文提出了X-Agent,这是一个创新的OVSS框架,它采用潜在语义感知的“代理”来协调跨模态注意力机制,同时优化潜在语义动态并增强其可感知性。大量的基准评估表明,X-Agent实现了最先进的性能,同时有效地增强了潜在语义显著性。
论文第一作者是厦门大学信息学院计算机科学与技术系2023级博士生李佳豪,通讯作者是其导师曲延云教授和谢源教授(华东师范大学),目前主要研究方向为多模态感知的复杂开放场景理解。
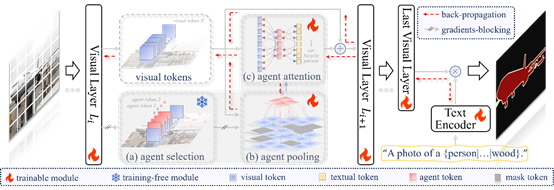
10. SynergyAmodal: Deocclude Anything with Text Control
介绍:针对模态补全任务在高质量数据上的匮乏问题,本文确定了三个关键要素:利用野外图像数据实现多样性,结合人类专业知识实现合理性,以及利用生成先验实现真实性。本文提出了SynergyAmodal,这是一个新颖的框架,用于共同合成具有全面形状和外观注释的野外非模态数据集。该框架通过数据-专家-模型三方协作整合了这些要素。具体来说,首先,本文设计了一个基于遮挡的自监督学习算法,以利用野外图像数据的多样性,将修复扩散模型微调为部分补全扩散模型。其次,本文建立了一个共同合成流程,迭代地过滤、优化、选择和注释部分补全扩散模型的初始去遮挡结果,通过人类专家指导和先验模型约束确保合理性和真实性。该流程生成了一个高质量的成对非模态数据集,涵盖了广泛的类别和尺度多样性,包括大约16K对样本。最后,本文在合成的数据集上训练了一个完整的补全扩散模型,并将文本提示作为条件信号纳入其中。大量实验表明,该框架在实现零样本泛化和文本可控性方面具有显著效果。
论文作者介绍:该论文第一作者是厦门大学信息学院2023级博士生李新阳,通讯作者是张声传副教授,由2024级硕士生伊承杰、2023级硕士生赖嘉炜、乐天亚洲私人有限公司首席科学家林明宝、2023级博士生曲延松和曹刘娟教授合作完成。

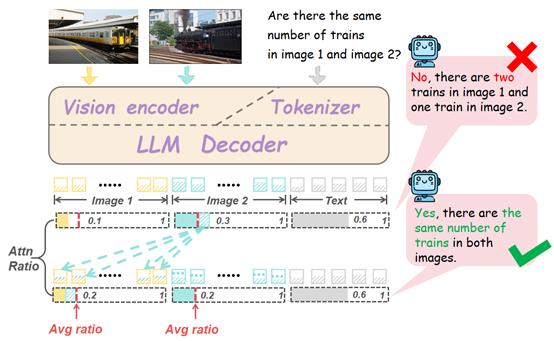
11. MIHBench: Benchmarking and Mitigating Multi-Image Hallucinations in Multimodal Large Language Models
近年来,多模态大语言模型(MLLMs)在生成任务中的“幻觉”问题引发了广泛关注。然而,现有研究几乎全部聚焦于单图像场景,对多图像设置下的幻觉现象仍属空白。针对这一研究缺口,本文首次系统性地探讨了多图像条件下的多模态幻觉问题,并提出全新基准 MIHBench,专为评估多图像场景中与对象相关的幻觉现象而设计。MIHBench涵盖三大核心任务:对象存在幻觉、对象数量幻觉与对象身份一致性幻觉,旨在全面考察模型在跨图像对象识别、数量推理及身份一致性判断等方面的语义理解能力。基于大规模实验分析,本文揭示了多图像幻觉发生的关键影响因素,包括:(1)图像输入数量与幻觉发生可能性之间的递进关系;(2)单图像幻觉倾向与多图像上下文中观察到的倾向之间的强相关性;(3)图像序列中相同对象比例和负样本位置对对象身份一致性幻觉发生的影响。为缓解上述问题,本文提出了一种动态注意力平衡机制(DAB),通过在图像间动态调整注意力分布,有效保持整体视觉关注稳定。实验结果显示,DAB显著提升了多个主流MLLM在多图像场景下的语义整合与推理稳定性,大幅降低幻觉生成频率。
该论文共同第一作者是厦门大学信息学院2022级本科生李嘉乐和2023级博士生吴明瑞,通讯作者是纪家沂博士后研究员,由孙晓帅教授、曹刘娟教授、纪荣嵘教授等共同合作完成。
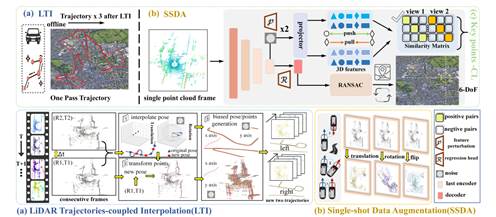
12. Unleashing the Power of Data Generation in One-Pass Outdoor LiDAR Localization
简介:现有的激光雷达隐式重定位的方法需要多条重复轨迹增加场景、位姿的丰富性以提升模型的性能。 由于GPS/INS的误差,多条轨迹之间的耦合性是欠佳的,同时也增加了人力采集成本。 本文首次提出了使用单趟轨迹定位的算法PELoc, 该研究观察到不同行驶轨迹的差异如存在反向行驶等现象,提出了单趟数据增强;针对多条轨迹耦合性欠佳提出了激光雷达耦合的插帧生成方法;针对相同位置视角/时相变换提出了关键点对比学习策略,此外本文提出了一个新的训练策略, 在每轮训练中随机去除5%连续帧,增强了单趟数据的轨迹多样性,实验结果表明PELoc在QEOxford和NCLT的绝大多数测试轨迹上均能接近或达到亚米级的定位精度。
该论文第一作者是厦门大学信息学院2024级博士生陈屹东,通讯作者是王程教授。并由李齐、杨煜阳、李文、敖晟助理教授共同完成。
13. HRSeg: High-Resolution Visual Perception and Enhancement for Reasoning Segmentation
简介:推理分割任务旨在根据用户隐含指令对图像中的目标进行分割,这些指令往往包含上下文线索和开放世界知识等隐性语义。尽管现有方法已取得显著进展,但仍受到感知分辨率不足的限制,原因在于视觉编码器通常在较低分辨率下进行预训练。单纯通过插值方式提升视觉编码器的位置嵌入,虽可略微改善性能,但代价是计算资源的大幅增加,收益有限。为解决这一问题,本文提出了一种高效的高分辨率细粒度感知模型。该模型包含两项关键创新:高分辨率感知模块和高分辨率增强模块。前者通过裁剪策略处理高分辨率图像,并融合局部与全局特征,实现多粒度的图像理解;后者则在掩码特征中引入高分辨率图像的细节信息,从而提升与文本特征的对齐精度,实现更为精确的目标分割。在多个基准数据集上的综合评估显示出HRSeg在性能上的全面优越性。
该论文共同第一作者是厦门大学信息学院2024级硕士生林玮煌和2023级博士生马祎炜,通讯作者是孙晓帅教授,由博士后研究员纪家沂、何淑婷(上海财经大学)、曹刘娟教授、纪荣嵘教授共同合作完成。
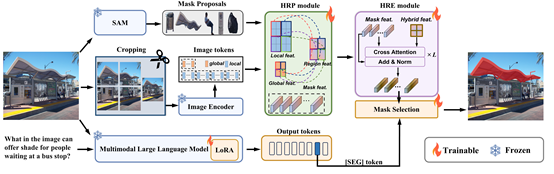
14. Phys4DGen: Physics-Compliant 4D Generation with Multi-Material Composition Perception
简介:4D生成旨在生成符合用户输入条件(如图像、3D内容)的动态3D内容,可广泛应用于动画、游戏、虚拟现实等场景。现有工作尝试引入物理仿真(如物质点法)使3D内容动态化,从而生成物理真实的4D内容。然而这类方法通常假设物体由单一材料构成,忽略了现实中物体常由多种异质材料组成,进而导致局部变形不真实,甚至在大变形下出现结构坍塌。此外,这类方法依赖用户手动设置材料属性。本文针对这些挑战,提出了一种物理驱动的4D生成框架—Phys4DGen,其引入了多材料复合感知到4D生成过程中,实现了快速的、用户友好的、物理真实的4D生成。具体而言,Phys4DGen首先将视觉分割模型(如SAM2)的能力扩展至3D空间,实现精确的表面材料分组;随后引入内部物理结构发现策略,建模物体内部的材料分布;最终通过蒸馏多模态大语言模型中蕴含的丰富物理知识,实现快速且自动的材料识别。在合成数据集和真实世界数据集上的实验表明,Phys4DGen能够有效感知复合物体中的多种异质材料,生成物理真实且高保真的4D内容,性能显著优于当前SOTA方法。
该论文第一作者是2023级硕士研究生林佳靖,通讯作者是江敏教授。并由王贞众助理教授、许得隽、蒋庶、龚云鹏共同完成。
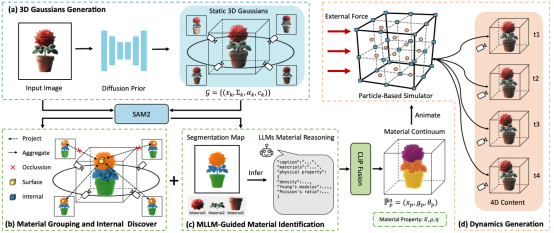
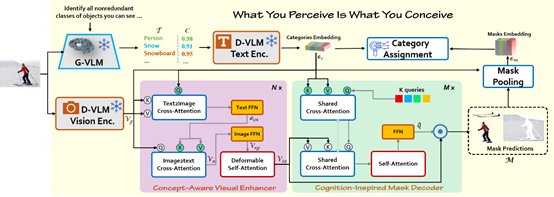
15. What You Perceive Is What You Conceive: A Cognition Inspired Framework for Open Vocabulary Image Segmentation
简介:本文提出了一种灵感源自人类视觉认知模型的新型图像分割方法。不同于传统先做无类别分割再与词汇对齐的流程,该方法首先通过生成型视觉-语言模型(G VLM)读取图像并生成可能出现的语义概念,从而形成“先构念再感知”的思维路径;紧接着,利用一个结合文本概念与视觉特征的模块进一步激发模型对这些语义线索的视觉敏感度;最后,使用一个认知启发式解码器根据预生成的概念线索,仅对相关类别子集执行细粒度分割,实现了更高效、更语义一致的图像理解过程。该框架不仅模拟了人类视觉“理解先于定位”的思路,也在多数据集上展示了对新词汇的良好泛化能力。这一建立在人类认知路径上的框架不仅改变了传统“先分割再匹配”的流程,还显著增强了开放词汇分割对新语义类别的泛化能力,为未来在动态词汇环境中的视觉理解任务提供了新的思路和方向。
该论文第一作者为厦门大学信息学院2023级博士生林将航,通讯作者是曹刘娟教授,由2024级硕士生胡越、沈江涛,腾讯优图实验室沈云航,张声传副教授,纪荣嵘教授等共同合作完成。
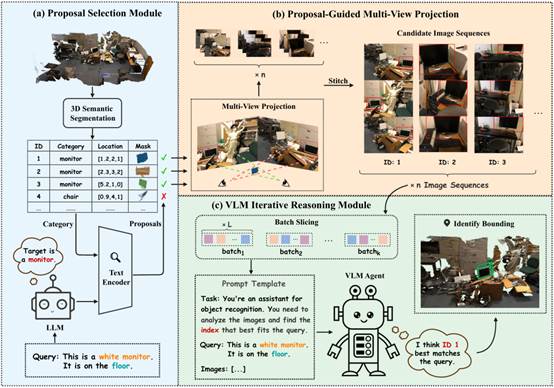
16. SeqVLM: Proposal-Guided Multi-View Sequences Reasoning via VLM for Zero-Shot 3D Visual Grounding
简介:3D视觉定位(3DVG)旨在利用自然语言在三维场景中定位目标物体。尽管全监督方法在特定条件下取得长足进展,但零样本3DVG因无需场景特定训练而更适用于真实应用场景。现有零样本方法受限于单视角推理,常出现空间理解不足和上下文信息缺失等问题。为此,本文提出一种新型零样本3D视觉定位框架SeqVLM,结合空间信息与多视角真实图像进行目标推理。该方法先通过3D语义分割生成候选区域并进行语义筛选,再将其多视角投影至图像序列以保留空间与上下文信息;同时引入动态调度机制,高效利用视觉语言模型的跨模态推理能力识别文本目标。实验结果表明,SeqVLM在多个基准数据集上均取得优异表现,展现出更强的泛化能力与实际应用潜力。
该论文的共同第一作者是厦门大学信息学院2024级硕士生林嘉文和2022级硕士生边诗然,共同通讯作者是曲延云教授和张亚超助理教授,由朱奕航(南京大学)、2024级博士生谭文斌、谢源教授(华东师范大学)等共同合作完成。
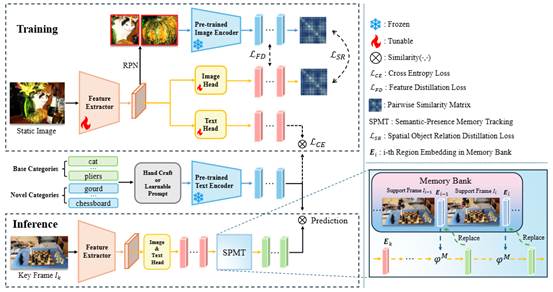
17. OV-VOD: Open-Vocabulary Video Object Detection
简介:传统视频目标检测(VOD)受限于预定义的封闭类别集,难以检测真实场景中的新物体。为此,本文首次明确定义了开放词汇视频目标检测(Open-Vocabulary VOD)任务,旨在检测视频流中来自开放类别(包括训练中未见的新类别)的物体。本文为该任务构建了基于LV-VIS、BURST和TAO数据集的评估基准,并提出了OV-VOD方法。该方法包含两个核心创新:语义存在记忆追踪模块利用记忆库跨帧传播物体特征以利用时间一致性;空间物体关系蒸馏损失捕获物体间空间依赖关系以增强知识蒸馏。实验表明,OV-VOD在多个视频数据集上展现出卓越的零样本泛化能力,在检测新类别方面显著优于现有图像级开放词汇检测方法,为开放世界的动态感知提供了新的有效解决方案。
该论文第一作者是厦门大学人工智能研究院2024级硕士生郑智鸿,通讯作者是王菡子教授,由信息学院2024级博士曹洋、高俊龙助理教授等共同合作完成。
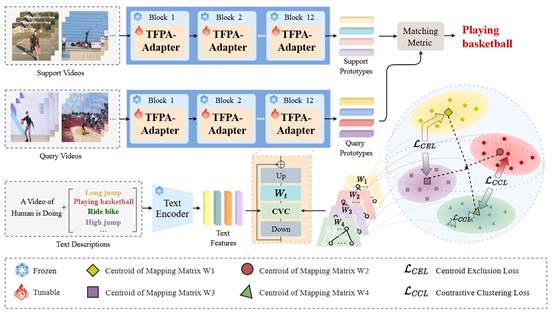
18. TFPA: Text Features Guided Dynamic Parameter Adjustment for Few Shot Action Recognition
简介:由于在小样本场景下数据有限,模型往往难以学习到具有泛化能力的参数,并陷入对源领域特定归纳偏置的过拟合。与现有方法不同,本文提出了一种基于文本特征引导的动态参数调整方法(TFPA),用于小样本行为识别。受向量空间基分解的启发,TFPA将传统线性层重构为可扩展的基矩阵库:每个线性层被解耦为多组基参数矩阵,其中每个基参数矩阵类似于线性层的基向量,共同构成参数空间的基底。坐标向量计算(CVC)模块利用文本信息作为语义引导,通过生成多个参数矩阵的组合系数来构建适用于特定任务的线性层参数。在多个小样本动作识别基准数据集展现出优异的泛化能力。
该论文的共同第一作者是厦门大学信息学院2022级硕士生郭涵羽、人工智能研究院2023级硕士生阙溯舟,通讯作者是王菡子教授,由高俊龙助理教授共同合作完成。
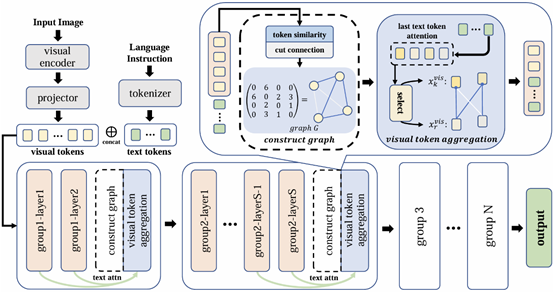
19. VISA: Group-wise Visual Token Selection and Aggregation via Graph Summarization for Efficient MLLMs Inference
本文提出了一种名为“分组视觉标记选择与聚合”(VISA)的新方法,用以解决多模大型语言模型(MLLM)中视觉标记过多导致推理效率低下的问题。与以往的标记修剪方法不同,本文方法在压缩视觉标记的同时保留了最多的视觉信息。首先提出了一个基于图的视觉标记聚合(VTA)模块。VTA将每个视觉标记视为一个节点,并根据视觉标记之间的语义相似性形成一个图。然后,基于该图将已移除标记的信息聚合到已保留的标记中,从而生成更紧凑的视觉标记表示。此外,本文还引入了一种分组标记选择策略(GTS),将视觉标记划分为已保留标记和已移除标记,并以来自每个组最后层的文本标记为指导。该策略逐步聚合视觉信息,增强了视觉信息提取过程的稳定性。在LLaVA-1.5、LLaVA-NeXT和Video-LLaVA上进行了多个基准测试的全面实验验证了本文方法的有效性且始终优于以前的方法,VISA在模型性能和推理速度之间实现了卓越的平衡。
该论文第一作者是厦门大学信息学院2023级硕士生蒋鹏飞,通讯作者是晁飞副教授,由李汉俊(腾讯优图)、赵凌览(腾讯优图)、鄢科(腾讯优图)、丁守鸿(腾讯优图)、纪荣嵘教授等共同合作完成。
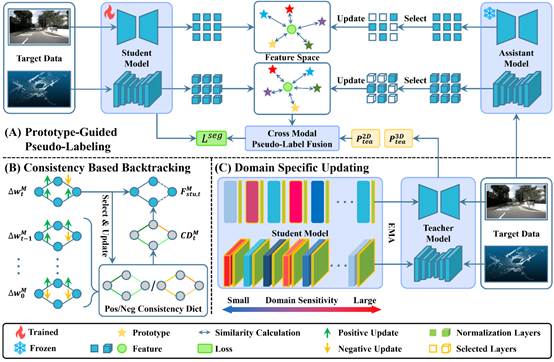
20. PLATO-TTA: Prototype-Guided Pseudo-Labeling and Adaptive Tuning for Multi-Modal Test-Time Adaptation of 3D Segmentation
简介: 多模态测试时自适应(Test-Time Adaptation, TTA)因其能够减少3D语义分割中对于标注的依赖并实现快速适应,正逐渐成为研究热点。现有方法通常依赖可学习的额外组件来缓解可靠性偏差,然而,在TTA场景中,这类基于学习的方法往往缺乏充分的训练。此外,大多数现有方法仅更新教师-学生框架中的归一化层,这限制了模型对领域偏移的建模能力。为此,我们提出了一种新颖的用于3D语义分割的多模态TTA方法PLATO-TTA,利用鲁棒原型的天然稳定性和教师-学生关键参数的自适应调节能力解决该问题。该方法包含三个核心模块:原型引导的伪标签生成模块(PGPL)、基于一致性的回溯模块(CBB) 以及领域特定更新模块(DSU)。PGPL 通过原型构建伪源域,并根据领域差异计算模态融合权重,生成鲁棒伪标签从而减少可靠性偏差;CBB 在防止灾难性遗忘的同时更新学生模型的全部参数,并引入参数回溯机制以增强稳定性;DSU 则仅使用学生模型中的领域特定参数来选择性地更新教师模型,实现快速适应并提供稳定指导。实验证明了 PLATO-TTA 的有效性。在存在严重可靠性偏差和显著领域差异的 Synthia→SemanticKITTI 场景中,PLATO-TTA带来了 6.3% 的性能提升,并在多个域自适应场景中达到了当前最优性能。
该论文的共同第一作者是信息学院2023级硕士生谢健祥和信息学院2021级博士生吴垚,通讯作者是其导师曲延云教授和谢源教授(华东师范大学),由张亚超助理教授、张晓沛(加州大学洛杉矶分校)共同合作完成。